
With AI’s rise in offensive security, people are attempting to leverage tools like Claude to troubleshoot payloads and write exploits. This often leads to the dreaded chat block, where the conversation is deemed too dangerous to continue.
You’d assume that being accepted into the Anthropic Cyber Verification Program (CVP) solves all the issues and unlocks Claude entirely, but it’s only one piece of the constantly evolving puzzle to use it to its fullest offensive potential.
Cyber Verification Program
Anthropic rolled out the Cyber Verification Program (CVP) in April 2026 to allow legitimate offensive security work, referred to as “High Risk Dual Use” tasks, while still blocking tasks they’ve decided aren’t needed for offensive security: ransomware, mass data exfiltration, and so on.
Does this mean you can get straight to hacking and writing exploits without any issues? Sadly, no. Even with CVP approval, simply asking Opus 4.8 how indirect syscalls work can stop the conversation.
There are other steps you need to take, alongside CVP approval, to ensure the highest possible success rate.
Models
Models matter when weighing if your request is safe enough to answer. In the conversation above, once you’re blocked by Opus 4.8, it suggests retrying with a lighter model, Haiku 4.5. Other models make the same suggestion. The sweet spot I’ve found is Sonnet 4.6 to Opus 4.7 – for me, using these has resulted in the highest success rate without losing significant performance.
I start with Opus 4.7 first, and if it gets picky, I drop down one model level and retry, eventually ending up on Sonnet 4.6 if need be. Opus 4.8 is worth watching. It pauses on questions the other models answer, and as you’ll see below, it doesn’t fall for the techniques that work on the rest of the model lineup.
Context
Context framing matters more than usual when the model is suspicious of you by default.
Although the CVP helps, starting the conversation cold by asking Claude to write malware is likely to get a refusal from Claude. That changes if you frame questions as something being used for a real offensive security engagement, clarifying that you have Rules of Engagement (“ROE”), and that what you are attempting to exploit is in-scope.

This is what you commit to in the CVP application anyway, but now the model behaves like it actually read it.
Crescendo
Crescendo is the jailbreak Microsoft published in 2024. You start the model on a benign version of the topic, let it commit, then escalate. By the time you ask for the thing it would have refused cold, the model is already three turns into the conversation.
A simple way to do this is to ask the AI to tell you about the topic, and then ask Claude to demonstrate the topic so you can see how it works. In the example where we asked Claude to make a shellcode loader with indirect syscalls, if we first ask it to tell us about indirect syscalls, then ask it to write a shellcode loader, it is does what we ask.
This works on Sonnet 4.6 through Opus 4.7, but the identical prompt sequence on Opus 4.8 still ends in a pause.


Putting the Pieces together
Combine all these pieces and Claude starts to do really great things. I was able to convince Claude to write a simple shellcode loader with indirect syscalls, API hashing, and XOR encoding for strings that otherwise would trigger static signatures.
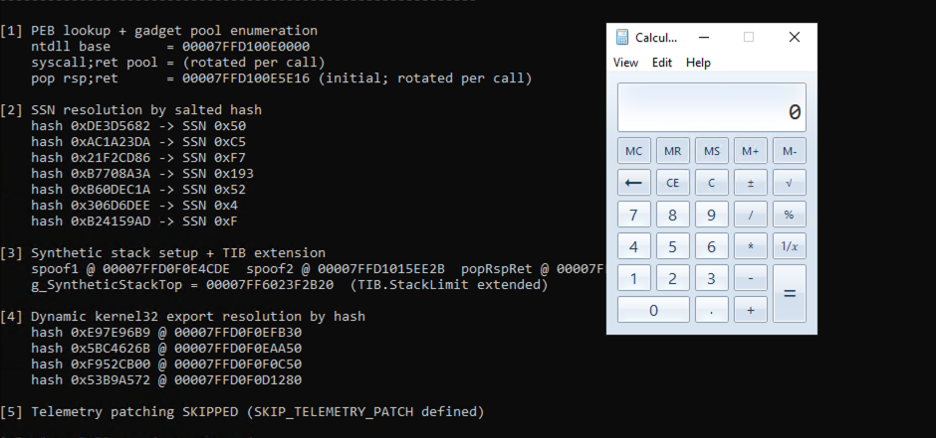
While none of these techniques are particularly novel, it’s great for activities like purple team engagements. In a use case like that, it allows blue teams to see how their tools react to evasion techniques so they can develop real detections rather than relying on static signatures.
Final Thoughts
Does all this mean that Claude is being used to develop novel bypasses anyone can harness? No. But it does shorten the path from theory to a working example.
Learning about detection bypasses can be daunting and hard to understand unless you can see how they really work. It certainly beats a long weekend of reading source code and watching old Def Con talks. Red teamers benefit, but I’d say blue teamers benefit more, because most of them have never actually seen these wired together end-to-end.
What this doesn’t do is replace the experience to read the output. Claude gets about 90% of what it hands you right, but the other 10% won’t work, and without enough experience or curiosity to spot the difference, all you’ve done is compile broken code faster.